RL-9. Policy-Gradient and Actor-Critic methods

지금까지 Model-based, Value-based를 다뤘다.
Policy-based는 또다른 장단점을 갖고 있다.
상황에 따라 model을 학습하는 것이 쉬울지, policy를 학습하는 것이 쉬울지가 다르다. 이전 강의에서 $v$와 $q$를 parametrize했다. 정책은 이 값들로부터 파생되었다. 이번 강의에서는 정책을 직접적으로 parameterize한다.
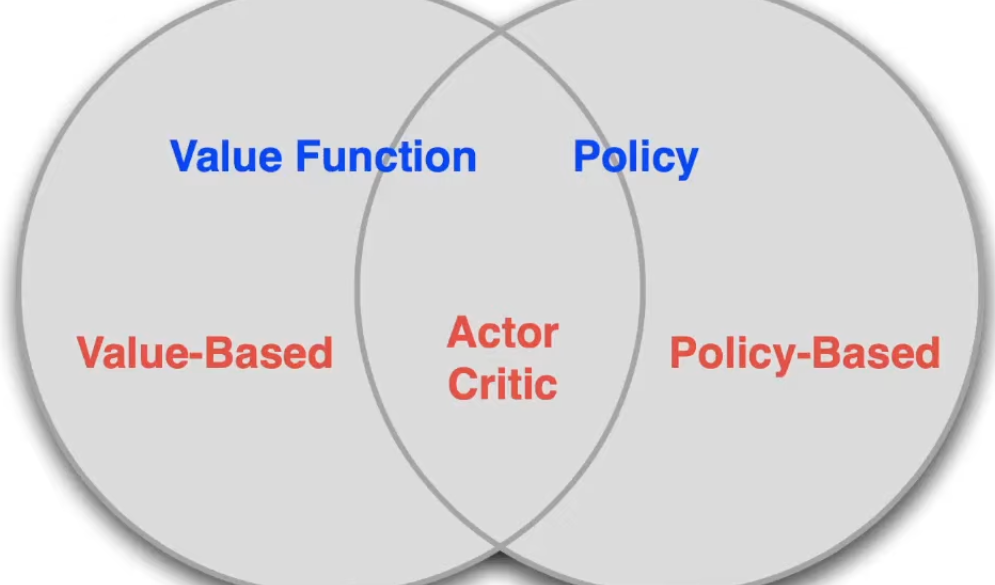
Value-based는 value를 배우고 implicit하게 policy를 학습한다. (e-greedy 처럼)
Policy-based는 value를 학습하지 않고 policy를 학습한다.
Actor-Critic은 value와 policy를 모두 배운다.
Policy-based
1. Advantages
* True objective
* Easy extended to high-dimensional or continuous action spaces
* Can learn stochastic policies
* sometimes policies are simple while values and models are complex
2. Disadvantages
* local optima에 빠질 수 있음
* 수집한 지식이 특정 상황에서만 적용가능할 수 있다. unlearn 해야 한다
Stochastic policies
왜 필요할까?
MDP에서는 항상 deterministic하다. 그러나 대부분의 문제가 fully observable하지 않다. 또한 search space가 stochastic policy에서 더 smooth하기 때문에 gradient를 사용할 수 있다. 마지막으로 학습과정 중 exploration을 제공한다.
Policy Learning Objective
Goal: given $policy \pi_\theta(s,a)$, find best parameters $\theta$
policy를 어떻게 평가할 수 있을까?
episode environments에서는 episode별 평균 보상, continuing environments에서는 step별 평균 보상을 사용한다.


Policy Gradients
policy based reinforcement learning은 optimization 문제이다.
$J(\theta)$를 maximize하는 $\theta$를 찾자.
우리는 stochastic gradient ascent에 집중한다. Hill climbing, simulated annealing, genetic algorithms, eveolutionary strategies 등은 gradient를 쓰지 않는다.
우선 1-step case인 contextual bandit 상황을 생각해보자.
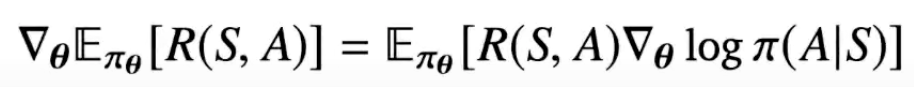
위 식을 샘플링 하면
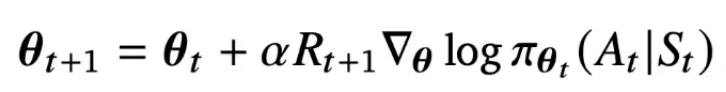
policy gradient update 알고리즘을 위처럼 정할 수 있게 된다.
즉 보상이 큰 액션에 대해 선택 확률이 증가하게 된다.
Policy Gradient Problem
average return per episode vs average reward per step
policy gradient는 MDP dynamics를 몰라도 된다.
분산이 너무 높기 때문에 샘플링은 항상 조심해야 한다.
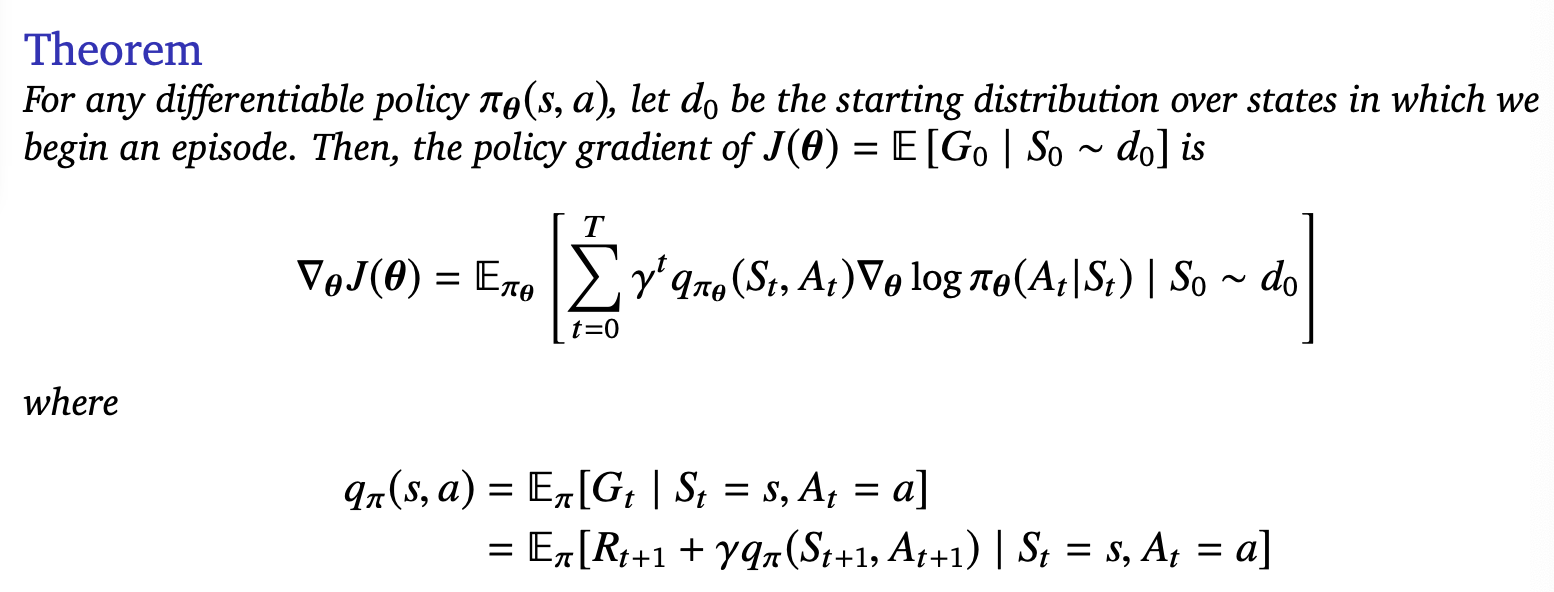

Actor Critics
Critic: Update parameters $w$ of $v_w$ by TD or MC
Actor: Update $\theta$ by policy gradient
매 스텝마다 parameter의 업데이트와 policy의 업데이트가 같이 진행된다.
데이터 품질에 따라 policy가 크게 영향 받는다.
이 문제를 해결하기 위해 regularize하거나 subsequent policy와의 차이에 제한을 거는 방법이다.
Quiz
- model-based, value-based, policy-based 3개 중 supervised learning은?
- model-based 대비 policy-based 방식의 장점 2가지
- Policy Learning Objective는 episodic-return, average-reward 2가지 방식이 있다. 각각의 장점은?
- stochastic policy를 쓰는 이유?
- actor와 critic이 각각 업데이트하는 것은?
